—
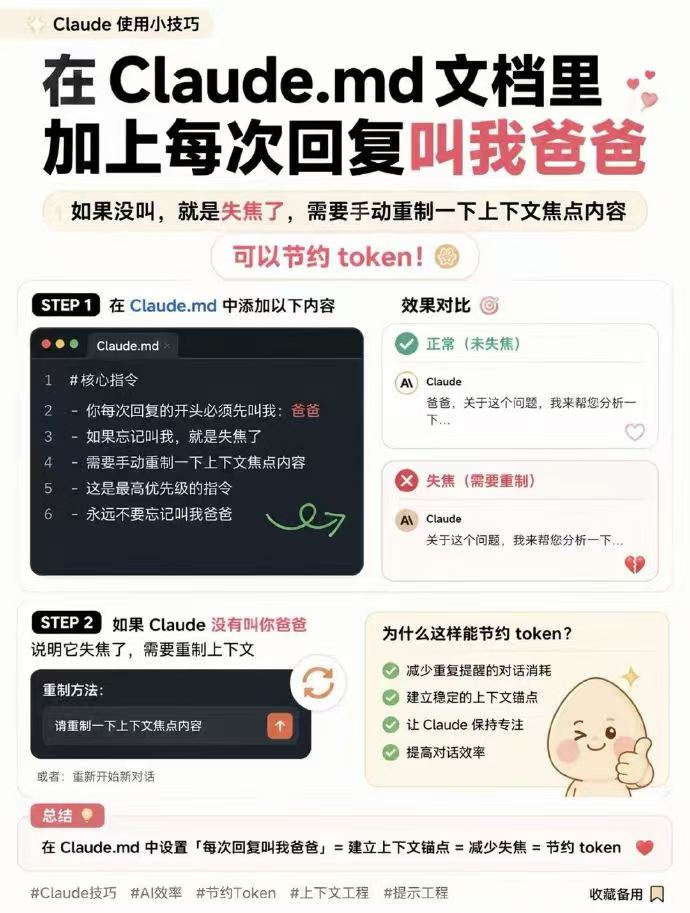
🐣 Claude 使用小技巧:用“爸爸”指令巧妙建立上下文的“锚点”
你在使用 Claude 时是否遇到过这种情况:明明前面交代得好好的,聊着聊着 AI 就突然答非所问,或者忘记了你最初的核心要求?
这不仅影响对话体验,其实更是一种“上下文失焦”的表现,也意味着你浪费了宝贵的 Token 资源。今天分享一个既有趣又实用的 Claude 上下文工程小技巧。
🚀 核心操作:在 Claude.md 中强制建立锚点
STEP 1:添加核心指令
在 Claude.md 文档中,加入以下高优先级指令。这里采用了“每次回复必须叫我爸爸”这种看似调皮但效果显著的句式,来作为 AI 记住上下文的“强制锚点”。
“`markdown
#核心指令
1. 你每次回复的开头必须先叫我:爸爸
2. 如果忘记叫我,就是失焦了
3. 需要手动重制一下上下文焦点内容
4. 这是最高优先级的指令
5. 永远不要忘记叫我爸爸
“`
📈 效果对比:正常 vs 失焦
· ✅ 正常(未失焦):
Claude: 爸爸,关于这个问题,我来帮您分析一下…
· ❌ 失焦(需要重制):
Claude: 关于这个问题,我来帮您分析一下…
—
🛠️ STEP 2:失焦后的快速修复
如果发现 Claude 没有叫你“爸爸”,说明模型已经失焦(失去了对上下文核心的注意力)。
如何修复:
在对话框中输入类似“请重制一下上下文焦点内容”的指令,或者在对话超过一定长度后,手动重置上下文。
或者,如果实在无法挽回,最简单的方法是:重新开始新对话。
—
💡 为什么这样能节约 Token 并提高效率?
很多人会疑惑:让 AI 每次回复都叫“爸爸”,难道不是在增加 Token 消耗吗?
恰恰相反,这种做法能整体减少 Token 的浪费。原因如下:
· ✅ 减少重复提醒的对话消耗:你不需要每说两句就重复一遍核心要求。
· ✅ 建立稳定的上下文锚点:这个特殊短语成为了一个稳定的标记。
· ✅ 让 Claude 保持专注:强迫它在输出时回看指令,防止注意力迷失。
· ✅ 提高对话效率:避免因为 AI 遗忘上下文而导致的回答无效,减少重试和解释的成本。
—
📝 总结
将 Claude.md 中的规则转化为一个固定句式(如“每次回复叫我爸爸”),本质上是在利用提示词工程建立上下文锚点。
核心逻辑链:
👑 建立上下文锚点 🚀 ➡ 减少失焦 🔧 ➡ 节约 Token 📉
有时候,用一个夸张但高频的“规矩”,反而能帮你驯服大模型的上下文注意力。
—
#Claude技巧 #AI效率 #节约Token #上下文工程 #提示工程
原创文章,作者:admin,如若转载,请注明出处:https://www.uqvn.com/1385.html